Are you leaking metadata? Here's a simple example to make your own tool to check!
Motivation
A lot of people know that a document may contain information they don't want to share with the world. But did you know that metadata in your pictures might have GPS coordinates embedded? Did you know that your powerpoint presentation might contain your username, ip addresses and other stuff that you might not share with the world. It's smart to check what information google, bing and others have collected about you and/or your business. It's also smart to have a remove metadata strategy so that you have control over your data.
You need to install the programming language Ruby and you need to install ruby gems to run the examples in this blogpost.
Manual search - google dorking
Google search engine offers a lot of powerful directives that can be used to provide you with tailored search results. Imagine that you'd like to search for PDF files, you can use the filetype:pdf directive:
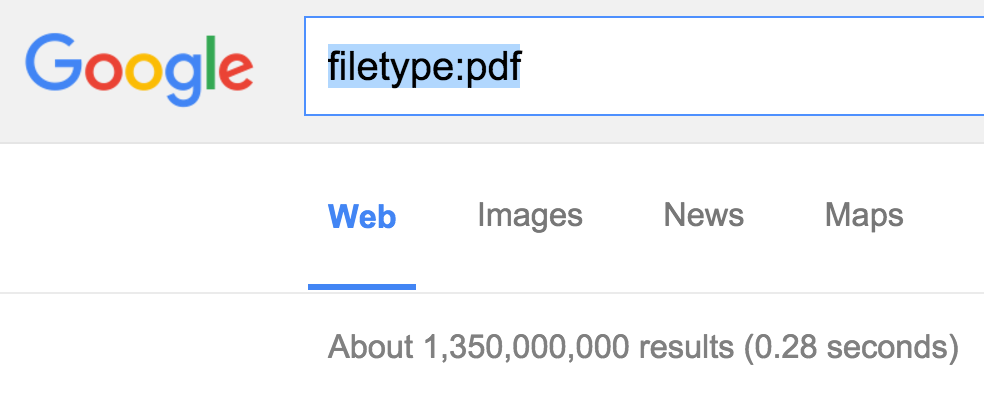
As you see we get over 1.3billion results, so there's a lot of PDFs out there. What if it was possible to only check for PDFs from the domain nsa.gov? Lets use the site: directive:
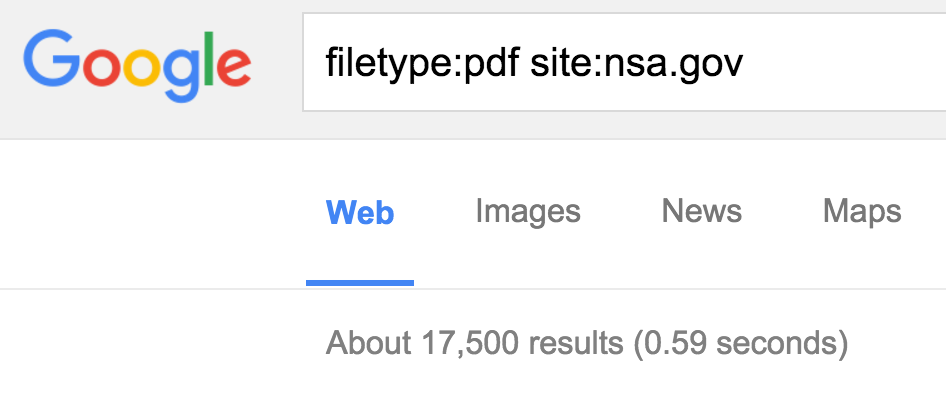
So Google has indexed approximately 17 thousand NSA PDF documents. How many of these files have metadata? All of them.
So what is metadata? It's data about data. You can find metadata in e.g files like ppt, pptx, doc, docx, pdf, gif, jpg, jpeg and much much more.
To show what metadata might look like I use exiftool which is easy to install in the most common operating systems like Windows, Linux and Mac.

So tell me, where was this picture taken?
Lets download the picture above and run it trough exiftool.
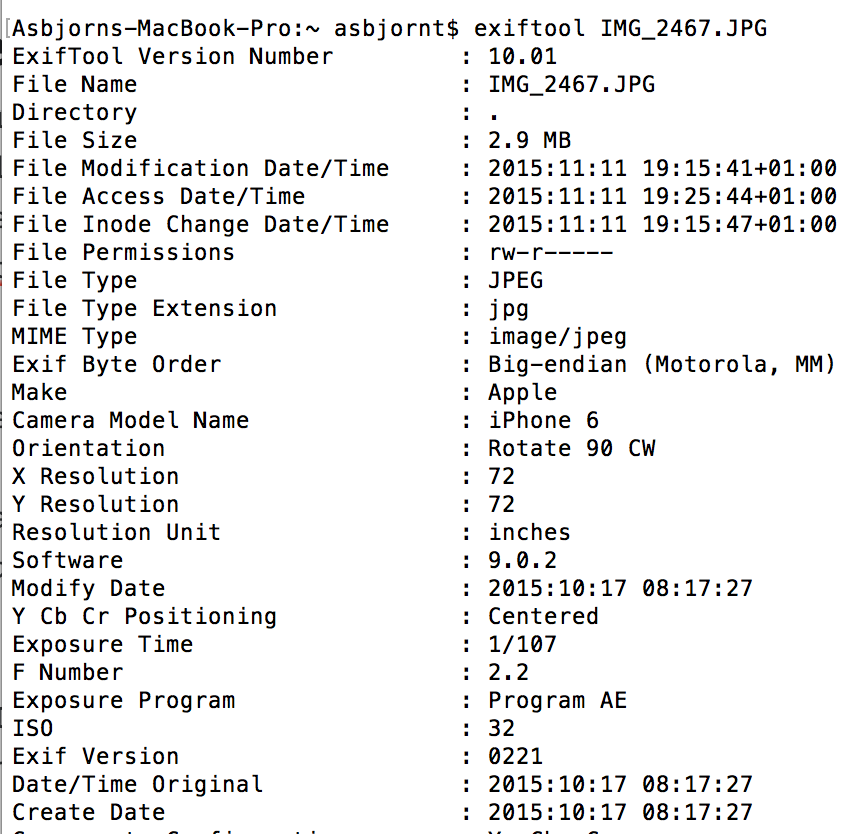
If you run the program you'll see how much metadata this picture contains. At the bottom you can see when it was shot (2015:10:17). If you read further down the result you'll even find the gps coordinates from where this picture is taken:

So it's pretty much straight forward to put the gps coordinates (59 deg 53' 37.61" N, 10 deg 38' 42.12" E) into google maps URL and the result is like this:
https://www.google.com/maps/@59.8937806,10.6450333,13z
You can copy and paste
59 deg 53' 37.61" N, 10 deg 38' 42.12" E
into the google maps search field removing deg resulting in this:
59 53' 37.61" N 10 38' 42.13” E
As you can see I obviously didn't take the picture at this location. I changed the gps coordinates with the exiftool like this:
exiftool -GPSLongitudeRef=E -GPSLongitude=10.6450333 - GPSLatitudeRef=N -GPSLatitude=59.8937806 *.JPG
So, what if I want to automate the google search for NSA's documents and read their metadata? Challenge accepted, and the tool I'd like to use is Ruby.
I first would like to try out the google-search gem installing it like this:
gem install google-search
After google-search is installed I can start interactive ruby in cmd in Windows or in a terminal in OSX or Linux with the command:
irb
and hit enter. Interactive ruby starts and we can start programming.
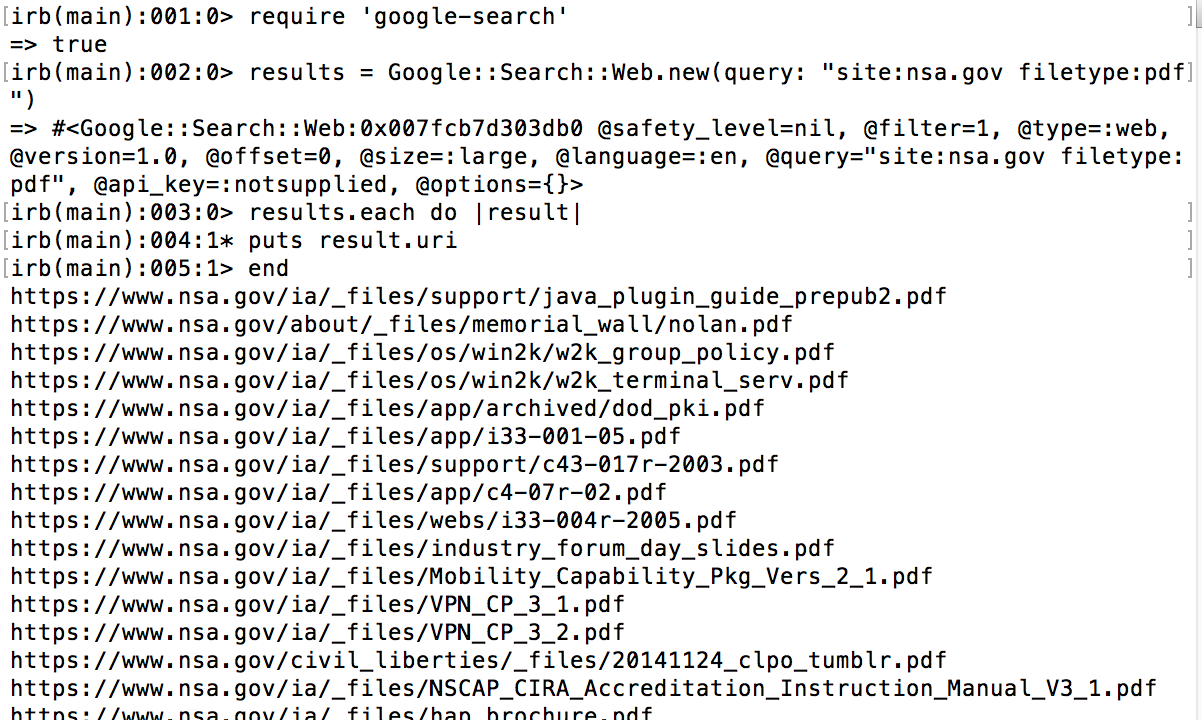
First we need to require the google-search module. The => true statement shows me that the module was imported successfully. Then I put a google search object into the results variable, making it ready to run the search. Note that we are passing the site and filetype directives to the google search, searching for NSA's PDFs. When looping through each result in results the google search is performed and the results are printed out. The list of the results is long so I truncated it in the picture.
Well now we clearly have a list of links to PDF documents linked to the NSA domain and we now want to download it all too. We now have to make our program a little more complex and to make it more readable I'll make a google-dork.rb file that we can modify and run easily from the command line. We need to install a library that makes it possible to download from Ruby and I'll use uri
gem install uri
The google-dork.rb for fetching the URLs from google looks like this:
require 'rubygems'
require 'google-search'
require 'uri'
site = "nsa.gov"
filetype = "pdf"
results = Google::Search::Web.new(query: "site:#{site} filetype:#{filetype}")
results.each do |result|
puts result.uri
end
Now we need to make the download the documents functionality and tell the program where to store the documents:
require 'rubygems'
require 'google-search'
require 'uri'
site = "nsa.gov"
filetype = "pdf"
results = Google::Search::Web.new(query: "site:#{site} filetype:#{filetype}")
results.each do |result|
puts "Downloading the file: #{result.uri}"
uri = URI(result.uri) #The url to the file to download
filename = URI(uri).path.split('/').last #Store only the file name
begin
download = open(uri)
IO.copy_stream(download, "/tmp/#{filename}") #Put the files to /tmp directory
# We need to handle a 404 - not found, or the program will crash
# therefore the use of rescue
rescue OpenURI::HTTPError => e
puts "Can't access #{site}"
puts e.message
next
end
end
The google-search module doesn't return more than ~60 results but if you use a google api you will get 100 searches a day, courtesy of Google, and then you will have to pay for searches beyond that. But the google-search module is useful enough for this explanation of metadata.
Next we have to extract metadata from the documents we have downloaded, and exiftool is a great tool for both extracting data and to set metadata in a file.
To run through all the files we downloaded to the /tmp directory I use the Dir.glob in Ruby:
Dir.glob("/tmp/*.#{filetype}") do |file|
puts "The file: #{file}"
end
Now we have to install the Ruby exiftool module:
gem install exiftool
This loop prints all the PDF files in the /tmp directory, and instead of just printing them out we make our program capable to extract the metadata from each files like this:
require 'exiftool'
Dir.glob("/tmp/*.#{filetype}") do |file|
e = Exiftool.new(file)
data = e.to_hash #Moving the results into a datastructure (hash)
end
Now all the metadata are extracted and placed into a hash called data. If you want to write out the hash to check your findings you could just make a for-loop printing out the key and the value of the key in the hash:
require 'exiftool'
Dir.glob("/tmp/*.#{filetype}") do |file|
e = Exiftool.new(file)
data = e.to_hash #Moving the results into a datastructure (hash)
#Iterating through each element in the hash writing the results to html file
for key in data.keys()
puts "Key: #{key} Value: #{data[key]}")
end
end
We'd like to have the results put into a web page which makes it much easier to read the findings. To do this we need to generate the html file in our ruby program. We'll make a file called metadata.html into the /tmp directory:
require 'exiftool'
html_file = File.open("/tmp/metadata.html", "w")
html_file.write("<html><meta charset=\"UTF-8\"><title>Metadata</title><body>")
Dir.glob("/tmp/*.#{filetype}") do |file|
html_file.write("<br/><br/>")
html_file.write("<table border=\"solid\"><th>Key</th><th>Value</th>")
e = Exiftool.new(file)
data = e.to_hash #Moving the results into a datastructure (hash)
#Iterating through each element in the hash writing the results to html file
for key in data.keys()
html_file.write("<tr><td>#{key}</td><td>#{data[key]}</td></tr>")
end
end
After running this program you can open your browser and navigate to your newly generated html file located in /tmp. You can write the URL to the file in the URL field in our browser like this:
file:///tmp/metadata.html
And press enter, and voila!
The complete program
#!/usr/bin/ruby
require 'rubygems'
require 'google-search'
require 'uri'
site = "nsa.gov"
filetype = "pdf"
counter = 1
results = Google::Search::Web.new(query: "site:#{site} filetype:#{filetype}")
results.each do |result|
puts "Downloading the file: #{result.uri} #{counter}"
counter += 1
uri = URI(result.uri) #The url to the file to download
filename = URI(uri).path.split('/').last #Store only the file name
begin
download = open(uri)
IO.copy_stream(download, "/tmp/#{filename}") #Put the files to /tmp directory
# We need to handle a 404 - not found, or the program will crash
# therefore the use of rescue
rescue OpenURI::HTTPError => e
puts "Can't access #{site}"
puts e.message
next
end
end
require 'exiftool'
html_file = File.open("/tmp/metadata.html", "w")
html_file.write("<html><meta charset=\"UTF-8\"><title>Metadata</title><body>")
Dir.glob("/tmp/*.#{filetype}") do |file|
html_file.write("<br/><br/>")
html_file.write("<table border=\"solid\"><th>Key</th><th>Value</th>")
e = Exiftool.new(file)
data = e.to_hash #Moving the results into a datastructure (hash)
#Iterating through each element in the hash writing the results to html file
for key in data.keys()
html_file.write("<tr><td>#{key}</td><td>#{data[key]}</td></tr>")
end
end
Fork me on Github
You can find this program in github if you want to try it out without doing coding yourself. You'll need git installed to do this:
git clone https://github.com/reglund/metadata.git
The program is for educational purposes only and to run this version the usage is:
ruby google-dork nsa.gov pdf 1
And if you already have downloaded the files and dont need them again run the program like this:
ruby google-dork nsa.gov pdf 0
Then the program will only extract the metadata from the PDF files you already have downloaded to /tmp.