Metadata in pictures embedded(!) in docx files
Motivation
This blog post startet naturally after finishing a previous blog post on Are you leaking metadata? Here's a simple example to make your own tool to check!. When you make a word document, I guess you often use images you have taken with your smart phone og camera? All these files contain metadata. What happens to the metadata when these images are imported into e.g. a word document? Is it possible to extract the images from a given word document? Are the pictures metadata still present?
Modern cameras and phones often writes a lot of metadata embedded in the pictures, e.g. GPS coordinates from where the picture was taken
I would like to raise the question: if washing documents of metadata is, or should be important to you, should you also wash images and files imported into your docx files?
In this blog post I will show how you easily can extract metadata from embedded JPG files in a docx document. I will also give you some Ruby code if you want to give it a go.
It is also possible to do this for pptx and maybe other files too, however I will only show the docx example just to show the concept.
Unzipping
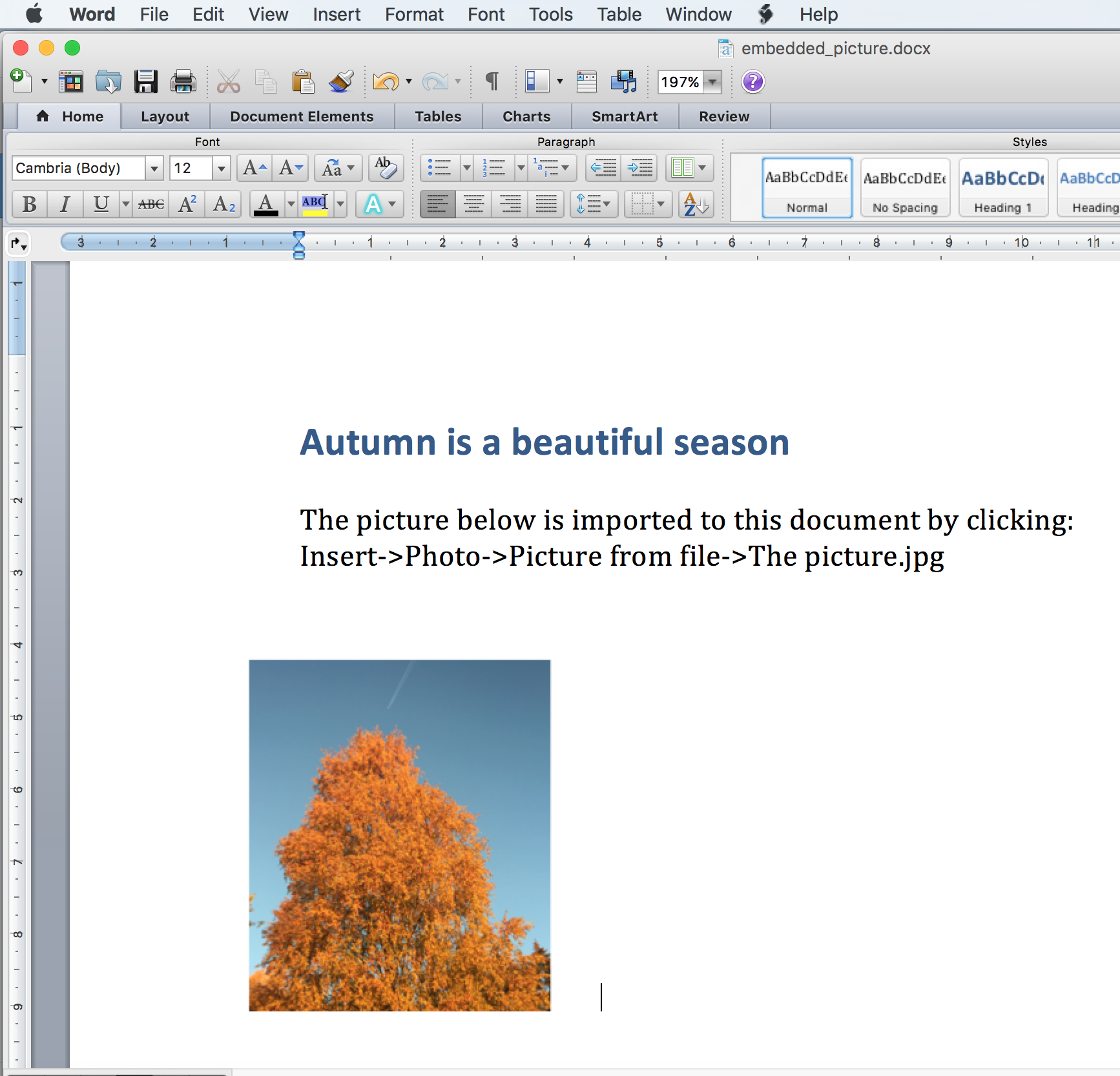
I made a simple word docx file containing some text and a picture I know contains GPS-coordinates in the metadata. Lets do a little experiment. Lets unzip a word docx file and look at the content being extracted:
I saved the docx document and entered the directory with my terminal:
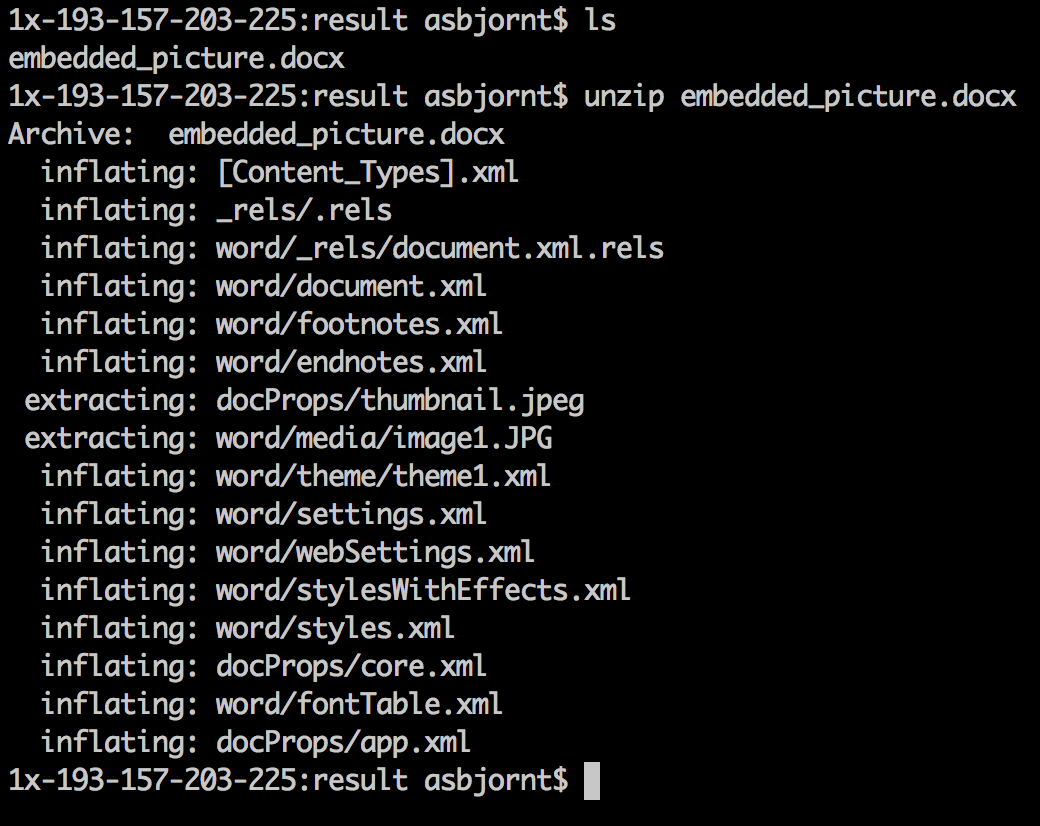
So it's possible to unzip docx files and look at the internals of the document. A quick search for where the JPG files are stored using my terminal:

I could only find one picture in the extracted data which makes sense since I only imported one picture to the document. The picture was renamed to image1.JPG by word and it was put in a folder /word/media/. Extracting metadata from this file with exiftool:
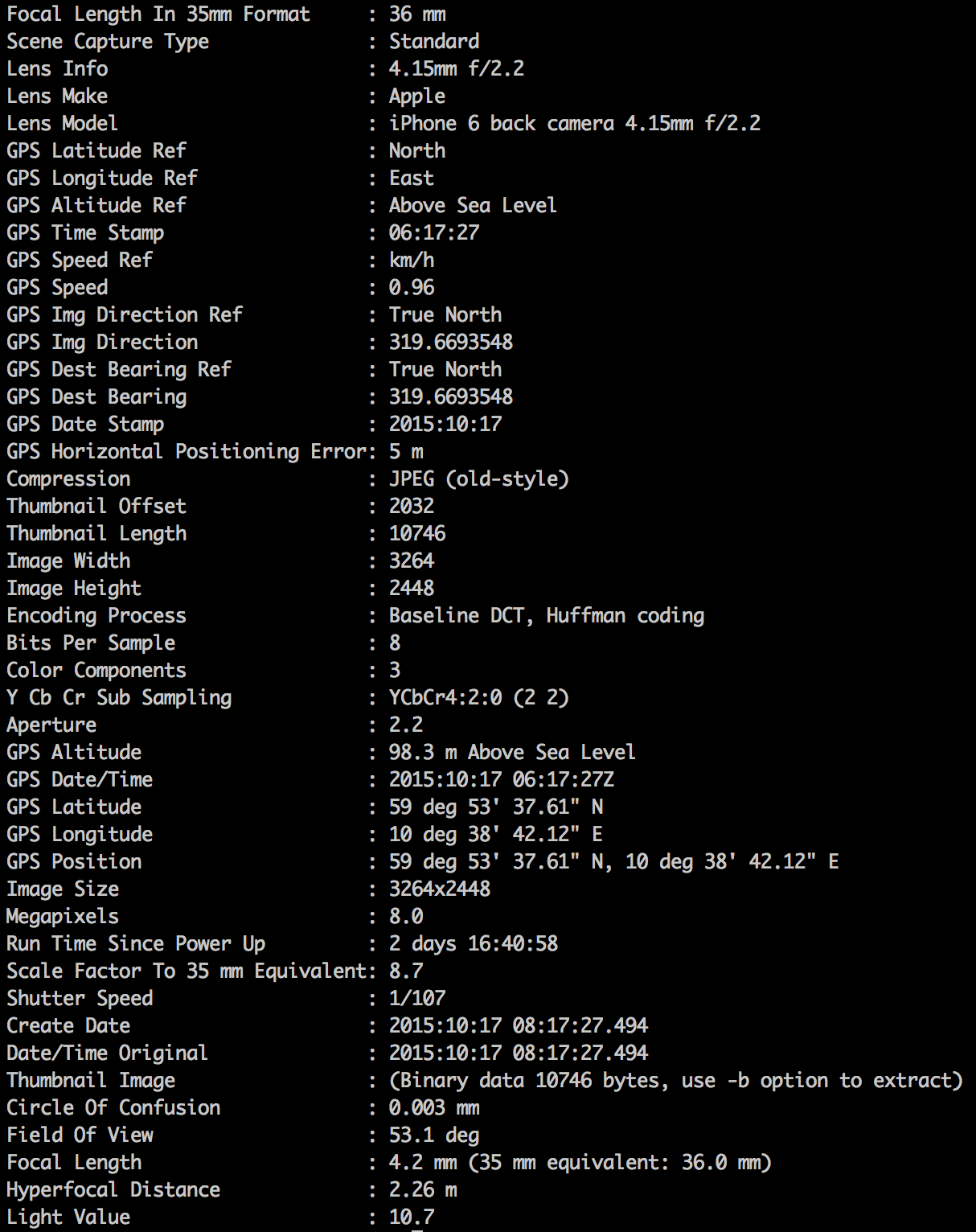
The picture still contained the original metadata. Above is a truncated version of the results.
In an earlier blog post I wrote about writing your own tool to collect metadata. You use this small program to download docx files from NASA and see if there are pictures embedded in them with interesting data.
Automated extraction of metadata in embedded files
Lets say you have run the google-dork.rb like this:
ruby google-dork.rb nasa.gov docx 1
This will download approximately 60 docx files to your /tmp folder. Lets make a ruby program and extract the data we are looking for and present it in an html file.
Step 1 - Glob through docx files
First we need to run through all the docx files we have downloaded into /tmp. I made a unpack folder inside /tmp to unpack the docx files:
def loop_over_files
Dir.glob("/tmp/*.docx") do |file|
unzip_file(file,'/tmp/unpack')
end
end
Step 2 - Unzip the files
Next we need to unzip all the docx files, however for each file that is unzipped all the folders and files will have the same name and we need to clear the folder after the document is processed to make room for the next document.
1x-192-157-203-225:metadata asbjornt$ ls /tmp/unpack/
[Content_Types].xml rels docProps word
1x-192-157-203-225:metadata asbjornt$
You need to install rubyzip to run the code below.
gem install rubyzip
The method for unzipping the files:
def unzip_file (file, destination)
puts "Unzipping #{file}"
clean_up("/tmp/unpack/")
Zip::File.open(file) do |zip_file|
zip_file.each do |f|
f_path = File.join(destination, f.name)
FileUtils.mkdir_p(File.dirname(f_path))
f.extract(f_path)
end
end
end
Step 3 - Clean the unpack folder
I need to clean the unpack folder to make room for the next folders and files containing the same names in the extracted files and folders:
def clean_up(dir)
puts "Cleaning up"
FileUtils.remove_dir(dir)
unless File.directory?(dir)
FileUtils.mkdir_p(dir)
end
end
Step 4 - Extracting the data
To extract the metadata we need to find where the pictures are stored, and for docx files the image files is stored in the /tmp/unpack/word/media/ folder. We need a method for extracting the metadata from the images:
def extract_data
puts "Extracting metadata"
path = "/tmp/unpack/word/media/"
$html_file.write("<html><meta charset=\"UTF-8\"><title>Metadata in embedded pictures</title><body>")
Dir.glob("#{path}/*.jpg") do |file|
puts "Running exiftool on #{file}"
$html_file.write("<br/><br/>")
$html_file.write("<table border=\"solid\"><th>Key</th><th>Value</th>")
e = Exiftool.new(file)
data = e.to_hash
for key in data.keys()
$html_file.write("<tr><td>#{key}</td><td>#{data[key]}</td></tr>")
end
end
end
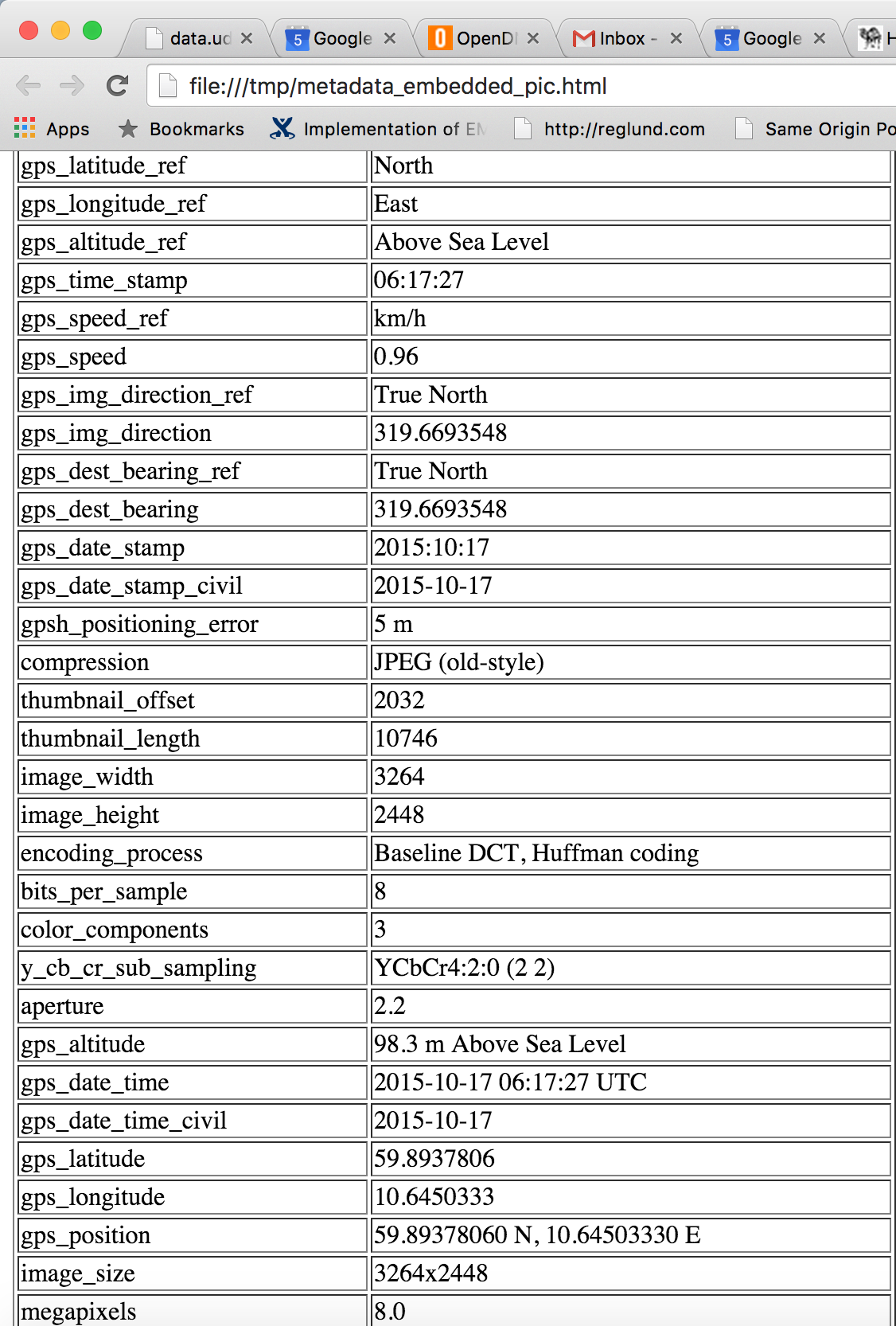
Results
This is a truncated version of the html result page generated by the small Ruby program. As you can see there are GPS findings. It's easy to get google maps to reveal the location:
https://www.google.com/maps/@59.8937806,10.6450333,13z
Putting it all together
The complete code should look like this:
#!/usr/bin/ruby
require 'exiftool'
require 'zip'
require 'fileutils'
def loop_over_files
Dir.glob("/tmp/*.docx") do |file|
unzip_file(file,'/tmp/unpack')
end
end
def unzip_file (file, destination)
puts "Unzipping #{file}"
clean_up("/tmp/unpack/")
Zip::File.open(file) do |zip_file|
zip_file.each do |f|
f_path = File.join(destination, f.name)
FileUtils.mkdir_p(File.dirname(f_path))
f.extract(f_path)
end
end
extract_data()
end
def extract_data
puts "Extracting metadata"
path = "/tmp/unpack/word/media/"
$html_file.write("<html><meta charset=\"UTF-8\"><title>Metadata in embedded pictures</title><body>")
Dir.glob("#{path}/*.jpg") do |file|
puts "Running exiftool on #{file}"
$html_file.write("<br/><br/>")
$html_file.write("<table border=\"solid\"><th>Key</th><th>Value</th>")
e = Exiftool.new(file)
data = e.to_hash
for key in data.keys()
$html_file.write("<tr><td>#{key}</td><td>#{data[key]}</td></tr>")
end
end
end
def clean_up(dir)
puts "Cleaning up"
FileUtils.remove_dir(dir)
unless File.directory?(dir)
FileUtils.mkdir_p(dir)
end
end
$html_file = File.open("/tmp/metadata_embedded_pic.html", "a")
loop_over_files()
$html_file.close
Run the code like this:
ruby extract_embedded.rb
Open the newly generated html file in your browser, it should be located in
/tmp/metadata_embedded_pic.html
Github
Get the code from github:
git clone https://github.com/reglund/metadata.git
Have fun!